The SEAD relational database contains data essential to our understanding of past environmental and climatic changes, and the human relationship with these changes.The data in SEAD primarily takes the form of biological and chemical/physical proxy data, i.e. fossil frequencies and measured variables derived from soil samples taken from archaeological and natural deposits. See the Concepts page for details of the methods involved in their collection. The database also includes geoarchaeological data from the analysis of ceramic thin sections, and dendrochronological results. Dates, such as radiocarbon or calendar dates, are linked to samples where available, as are bibliographic information and extensive metadata. These allow for a large degree of linking with other databases. Further datasets, although few in number, include the results from modern biological sampling (insects, pollen, plants). Modern ecological reference data are included for most insect species, allowing extensive and detailed palaeoenvironmental reconstructions to be undertaken. These data will be expanded to cover plants with time and in collaboration with other projects.
Database system and structure
SEAD is a relational database, where data are stored in a complex but efficient web of database tables. The structure allows for efficient data retrieval and querying, in other words, it allows complex questions to be asked of the data, and easier integration with other data sources at mulitple levels. Click the image below for a more readable, if not more understandable, pdf version.
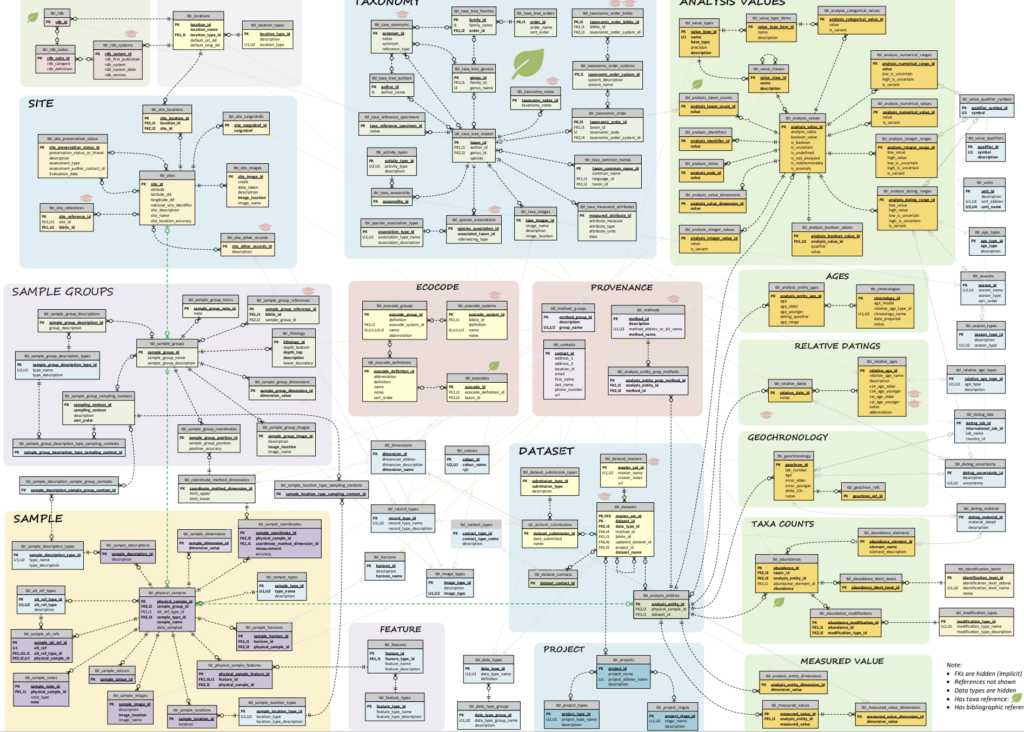
SEAD database model
The SEAD structure is largely based on the archaeological method and process, more specifically, environmental archaeology. The data stored in SEAD has an inherent hierarchy, with the site at the top level, and the samples (and the results from analyses performed on these) at the lower level. A conceptual model for the SEAD database model can be viewed below.
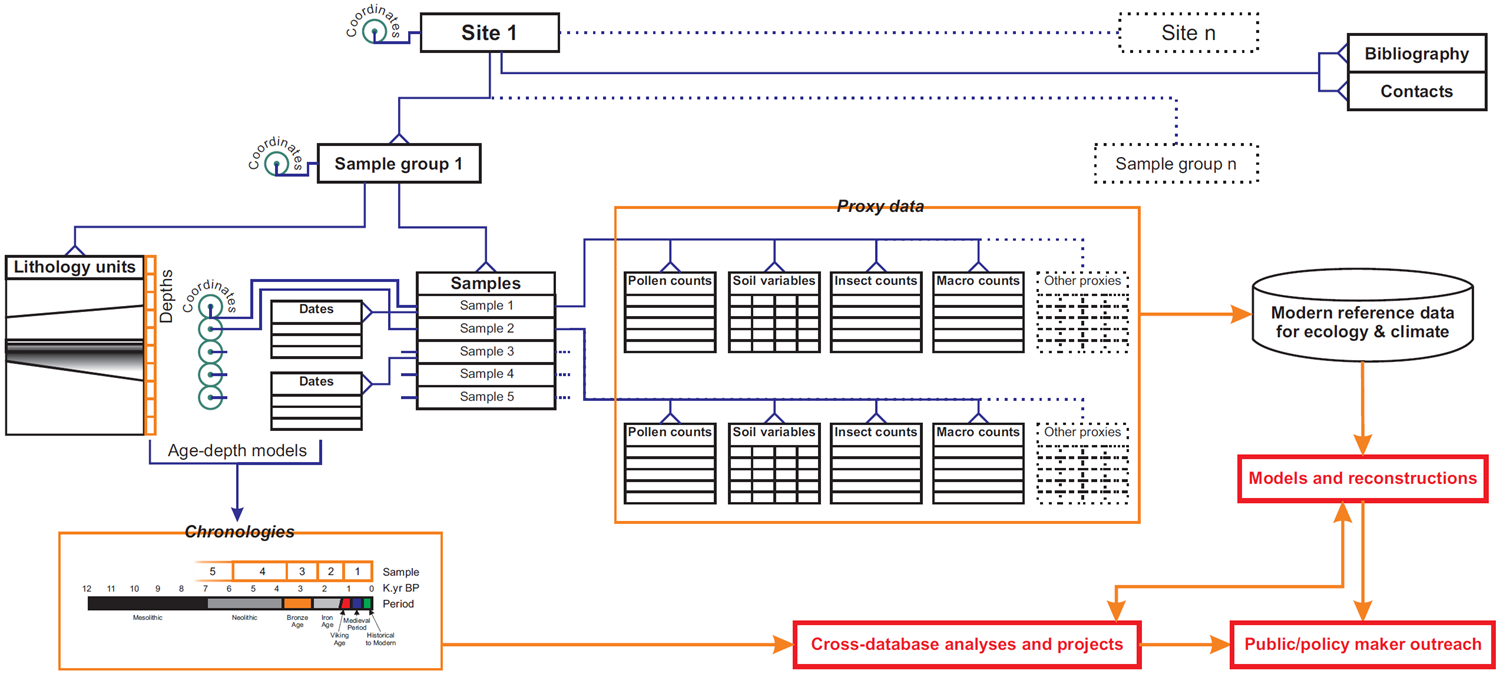
SEAD conceptual database model
quality assurance and data dissemination
A number of mechanisms ensure that only reliable data are available through SEAD. All submitted data are subject to evaluation by a clearing house where any inconsistancies or problems with the data are ironed out in communication with the data provider. This model is integral to the project structure, and considered essential for ensuring transparency in scientific research. The database also includes the facility for flagging data quality, authorship and origin, method descriptions and a number of other hard wired quality indicators and tracers.
![]()
Online data delivery and software tools
SEAD provide online access to the raw data, and a number of simple analysis tools to help interpretation. A number of these tools will be derived from those in the BugsCEP system, including those for climate and environmental reconstruction from fossil beetle data. See the resources and downloads page for more information.